06 Buffer Pools
Introduction
The DBMS is responsible for managing its memory and moving data back and forth from the disk. Since, for the most part, data cannot be directly operated in the disk, any database must be able to efficiently move data represented as files from disk into memory so that it can be used.
Another way to think of this problem is in terms of spatial and temporal control:
Spatial Control aims to keep pages that are used together often as physically close together as possible on disk.
Temporal Control aims to minimize the number of reads from disk
Locks vs Latches
Discussed more in depth in 09 Index Concurrency Control
Locks: A lock is a higher-level, logical primitive that protects the contents of a database (e.g., tuples, tables, databases) from other transactions. Transactions (queries) will hold a lock for its entire duration. Database systems can expose to the user which locks are being held as queries are run. Locks need to be able to rollback changes.
- Purpose: Locks are used to control access between different transactions or external operations accessing the database. They ensure that multiple users or processes can work on the database without interfering with each other’s data.
Latches: A latch is a low-level protection primitive that the DBMS uses for the critical sections in its internal data structures (e.g., hash tables, regions of memory). Latches are held for only the duration of the operation being made. Latches do not need to be able to rollback changes.
- Purpose: Latches are used internally by the database system to protect the critical structures of the database itself while they are being accessed or modified. This is about safeguarding the database’s operations, not user transactions.
Locks are not necessary in a strictly single-query, single-transaction environment due to the absence of concurrent access. If a database engine is running in a single-threaded environment where only one process accesses and modifies the database at a time, the need for latches can be significantly reduced or even eliminated.
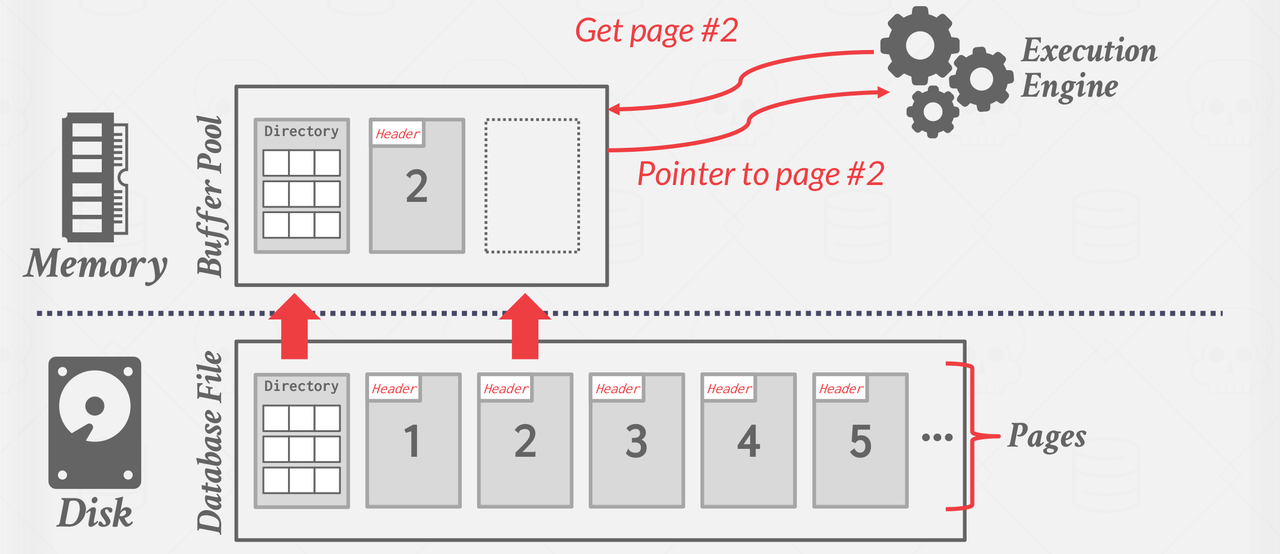
Buffer Pool
The buffer pool is an in-memory cache of pages read from disk. The buffer pool’s region of memory organized as an array of fixed size pages. Each array entry is called a frame. The database system can search the buffer pool first. Only if the page is not found, the system fetches a copy of the page from the disk.
Buffer Pool Meta-data
The buffer pool must maintain certain meta-data in order to be used efficiently and correctly.
The page table is an in-memory hash table that keeps track of pages that are currently in memory. It maps page ids to frame locations in the buffer pool. page table allows the database system to quickly find out whether a requested page is already loaded into RAM and where exactly it is located.
(the page table is not to be confused with the page directory)
page directory maps page IDs to their locations in the database files on disk. Page directory tells the system where each page can be found in the physical database files.
The page table also maintains additional meta-data per page, a dirty-flag and a pin/reference counter:
The dirty flag is set by a thread whenever it modifies a page.
The pin/reference Counter tracks the number of threads that are currently accessing that page (either reading or modifying it).
Memory Allocation Policies
Memory in the database is allocated for the buffer pool according to two policies:
Global policies deal with decisions that the DBMS should make to benefit the entire workload that is being executed.
Local policies make decisions that will make a single query or transaction run faster, even if it isn’t good for the entire workload.
Buffer Pool Optimization
Multiple Buffer Pools
The DBMS can maintain multiple buffer pools for different purposes. This method can
help reduce latch contention and improves locality.
Pre-fetching
While the first set of pages is being processed, the second can be pre-fetched into the buffer pool. This method is commonly used by DBMS’s when accessing many pages sequentially.
Scan Sharing (Synchronized Scans)
If a query starts a scan and if there one already doing this, then the DBMS will attach the second query’s cursor to the existing cursor.
- Independence vs. Coordination: In standard buffer operations, each query independently checks if its required data is in the buffer pool and accesses it if present. There’s no coordination in how the data is read into the buffer pool — it’s reactive, based on individual query needs.
- Proactive Coordination: Scan sharing is a proactive approach where the system recognizes that multiple processes will need the same data and coordinates the data loading into the buffer pool in such a way that it is optimized for all involved queries. It’s not just about avoiding duplicate reads from the disk; it’s about optimizing the process of reading from the disk when a known large-scale need exists.
Practical Example
Suppose multiple analysts need to perform a data-intensive operation that scans a large sales dataset:
- Without Scan Sharing: Each analyst’s query would check if the needed data pages are in the buffer pool and trigger a disk read if not found, potentially leading to multiple reads of the same pages by different queries if not perfectly synchronized.
- With Scan Sharing: The database system orchestrates the disk read as part of the first query that initiates the scan, and specifically manages the data loading process so that all subsequent queries benefit from this initial read, without each having to manage their own separate data load.
Buffer Pool Bypass
This works well if operator needs to read a large sequence of pages that are contiguous on disk.
Buffer Replacement Policies
When the DBMS needs to free up a frame to make room for a new page, it must decide which page to evict from the buffer pool. A replacement policy is an algorithm that the DBMS implements that makes a decision on which pages to evict from buffer pool when it needs space.
Least Recently Used (LRU)
This policy maintains a timestamp of when each page was last accessed. The DBMS picks to evict the page with the oldest timestamp. This timestamp can be stored in a separate data structure, such as a queue, to allow for sorting and improve efficiency by reducing sort time on eviction.
CLOCK
The CLOCK policy is an approximation of LRU without needing a separate timestamp per page. In the CLOCK policy, each page is given a reference bit. When a page is accessed, set to 1. When in need of sweeping, cycle through the pages to change the 1 bit to 0, and removing the 0 bits with other pages.
what if:
- A process access a page, turning the bit to 1
- CLOCK sweep happens when the process is still accessing the page, changing the bit to 0
- CLOCK sweep happens again when the process has not finished accessing the page yet.
In a scenario like this, the CLOCK algorithm’s behavior is designed not to compromise the integrity or availability of data that might still be in active use. The use bit is a tool for managing memory efficiently, but it works alongside other mechanisms that ensure data is not lost or evicted prematurely while still in use. The additional protections like pinning or latching are critical in situations where a page might be accessed over extended periods, particularly in high-concurrency environments.
Alternatives
LRU and CLOCK are susceptible to sequential flooding, where the buffer pool’s contents are corrupted due to a sequential scan.
There are three solutions to address the shortcomings of LRU and CLOCK policies:
- LRU-K keeps track of last K times a pages was accessed for a better judgement
- localization per query only using a certain number of frames for a sequential scan query (localize)
- priority hints have priority queue for the frames, indicating if a page is important or not.
Dirty Pages
Dirty pages are pages in buffer pool that have been modified but not written back to disk. There are two methods to handling pages with dirty bits. The fastest option is to drop any page in the buffer pool that is not dirty. A slower method is to write back dirty pages to disk to ensure that its changes are persisted. One way to avoid the problem of having to write out pages unnecessarily is background writing. Through background writing, the DBMS can periodically walk through the page table and write dirty pages to disk. When a dirty page is safely written, the DBMS can either evict the page or just unset the dirty flag.
Other Memory Pools
The DBMS needs memory for things other than just tuples and indexes. These other memory pools may not always backed by disk depending on implementation.
• Sorting + Join Buffers
• Query Caches
• Maintenance Buffers
• Log Buffers
• Dictionary Caches
OS Page Cache
Most disk operations go through the OS API. Unless explicitly told otherwise, the OS maintains its own filesystem cache. Most DBMS use direct I/O to bypass the OS’s cache in order to avoid redundant copies of pages and having to manage different eviction policies.
Postgres is an example of a database system that uses the OS’s Page Cache.
Disk I/O Scheduling
The DBMS maintains internal queue(s) to track page read/write requests from the entire system. The priority of the tasks are determined based on several factors:
• Sequencial vs. Random I/O
• Critical Path Task vs. Background Task
• Table vs. Index vs. Log vs. Ephemeral Data
• Transaction Information
• User-based SLAs
Personal Notes
The best scenario would be to have everything in RAM, but since we cannot, we use buffer pools.
Row level locking vs Page level locking. Is row level locking objectively better?
Buffer Pools
Buffer Replacement Policies:
LRU, CLOCK - naive solution that face sequential flooding
LRU-K, localization per query, priority hints - better
Smarter policies in study:
machine learning based caching
multi tier caching
content aware caching
anti-caching (Andy Pavlo)
but why not just buffer pool bypass?
the trend in performance vs cost, (or time vs space)?
Asterix DB uses extensible hashing