08 Tree Indexes
Table Indexes
There are a number of different data structures one can use inside of a database system. For table indexes, which may involve queries with range scans, a hash table may not be the best option since it’s inherently unordered.
A table index is a replica of a subset of a table’s columns that is organized and/or sorted for efficient access using a subset of those attributes. Although more indexes makes looking up queries faster, indexes also use storage and require maintenance. Plus, there are concurrency concerns with respect to keeping them in sync.
B+Tree
A B+Tree is a self-balancing tree data structure that keeps data sorted and allows searches, sequential access, insertion, and deletion in O(log(n)). It is optimized for disk-oriented DMBS’s that read/write large blocks of data.
Almost every modern DBMS that supports order-preserving indexes uses a B+Tree. The primary difference between the original B-Tree and the B+Tree is that B+Trees stores keys and values in all nodes, while B+Trees store values only in leaf nodes.
- Modern B+Tree implementations combine features from other B-Tree variants, such as the sibling pointers used in the Blink-Tree.
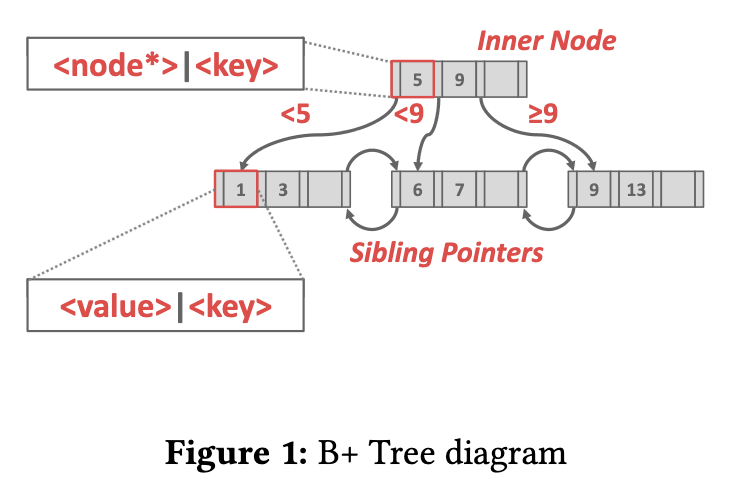
Formally, a B+Tree is an M-way search tree with the following properties:
- It is perfectly balanced
- Every inner node other than the root is at least half full
- Every inner node with k keys has k+1 non-null children
For leaf nodes, the keys are derived from the attribute(s) that the index is based on.
For inner nodes, the values contain pointers to other nodes, and the keys can be through of as guide posts.
Depending on the index type, null keys will be clustered in either the first leaf node or the last leaf node.
Duplication Keys
There are problems that arise when the keys are duplicate in B+trees.
There are two approaches to duplicate keys in a B+Tree.
- The first approach is to append record IDs as part of the key. Since each tuple’s record ID is unique, this will ensure that all keys are identifiable.
- The second approach is to allow leaf nodes to spill into overflow nodes that contain the duplicate keys. Although no redundant information is stored, this approach is more complex to maintain and modify.
Clustered Indexes
The table is stored in the sort order specified by the primary key, as either heap- or index-organized storage. Since some DBMSs always use a clustered index, they will automatically make a hidden row id primary key if a table doesn’t have an explicit one, but others cannot use them at all.
Heap Clustering
Tuples are sorted in the heap’s pages using the order specified by a clustering index. DBMS can jump directly to the pages if clustering index’s attributes are used to access tuples.
Index Scan Page Sorting
Since directly retrieving tuples from an unclustered index is inefficient, the DBMS can first figure out all the tuples that it needs and then sort them based on their page id. This way, each page will only need to be fetched exactly once.
B+Tree Design Choices
Node Size
Depending on the storage medium, we may prefer larger or smaller node sizes.
For example:
- Nodes stored on hard drives are usually on the order of megabytes in size to reduce the number of seeks needed to find data and amortize the expensive disk read over a large chunk of data.
- In-memory databases may use page sizes as small as 512 bytes in order to fit the entire page into the CPU cache as well as to decrease data fragmentation.
This choice can also be dependent on the type of workload, as point queries would prefer as small a page as possible to reduce the amount of unnecessary extra info loaded, while a large sequential scan might prefer large pages to reduce the number of fetches it needs to do.
Merge Threshold
While B+Trees have a rule about merging underflowed nodes after a delete, sometimes it may be beneficial to temporarily violate the rule to reduce the number of deletion operations.
There are merge strategy that keeps small nodes in the tree and rebuilds it later, which made the tree unbalanced (as in Postgres). We will not discuss this in the lecture.
Variable Length Keys
Currently we have only discussed B+Trees with fixed length keys. However we may also want to support variable length keys, such as the case where a small subset of large keys lead to a lot of wasted space. There are several approaches to this:
- Pointers:
Instead of storing the keys directly, we could just store a pointer to the key. Due to the inefficiency of having to chase a pointer for each key, the only place that uses this method in production is embedded devices, where its tiny registers and cache may benefit from such space savings.Nobody does this now in disk based system. Too many disk IO
- Variable Length Nodes
We could also still store the keys like normal and allow for variable length nodes. This is generally infeasible and largely not used due to the significant memory management overhead of dealing with variable length nodes.Each page has a different size. Not done in real world. Only in academic systems.
- Padding
Instead of varying the key size, we could set each key’s size to the size of the maximum key and pad out all the shorter keys. In most cases this is a massive waste of memory, so you don’t see this used by anyone either.Rare, not used.
- Key Map/Indirection
The method that nearly everyone uses is replacing the keys with an index to the key-value pair in a separate dictionary. This offers significant space savings and potentially shortcuts point queries (since the key-value pair the index points to is the exact same as the one pointed to by leaf nodes). Due to the small size of the dictionary index value, there is enough space to place a prefix of each key alongside the index, potentially allowing some index searching and leaf scanning to not even have to chase the pointer (if the prefix is at all different from the search key).Has another storage to store mapping, then key is fixed size, however, it does not necessarily reduce the total amount of data stored. Actually, it stores more.
Intra-Node Search
Once we reach a node, we still need to search within the node (either to find the next node from an inner node, or to find our key value in a leaf node). While this is relatively simple, there are still some tradeoffs to consider:
- Linear: O(n) per search
- Binary: O(ln(n)) search
- Interpolation: This method takes advantage of any metadata stored about the node (such as max element, min element, average, etc.) and uses it to generate an approximate location of the key. Despite being the fastest method we have given, this method is only seen in academic databases due to its limited applicability to keys with certain properties (like integers) and complexity.
*Estimate position assuming that keys are distributed uniformly.
Optimizations
Pointer Swizzling
Because each node of a B+Tree is stored in a page from the buffer pool, each time we load a new page we need to fetch it from the buffer pool, requiring latching and lookups. To skip this step entirely, we could store the actual raw pointers in place of the page IDs (known as ”swizzling”), preventing a buffer pool fetch entirely.
Replace disk address to memory address. Need to make sure memory address is not replaced (page may be flushed)don’t store this address on disk.
Bulk Insert
When a B+Tree is initially built, having to insert each key the usual way would lead to constant split operations. Since we already give leaves sibling pointers, initial insertion of data is much more efficient if we construct a sorted linked list of leaf nodes and then easily build the index from the bottom up using the first key from each leaf node.
Build the tree bottom up.
Prefix Compression
Most of the time when we have keys in the same node there will be some partial overlap of some prefix of each key. Instead of storing this prefix as part of each key multiple times, we can simply store the prefix once at the beginning of the node and then only include the unique sections of each key in each slot.
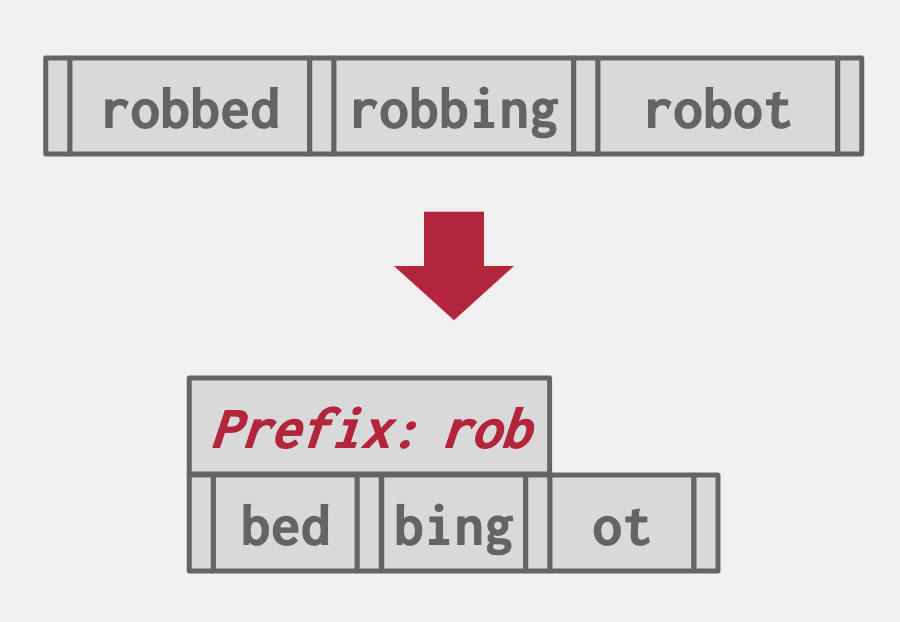
Typically applied in inner nodes (not leaf).
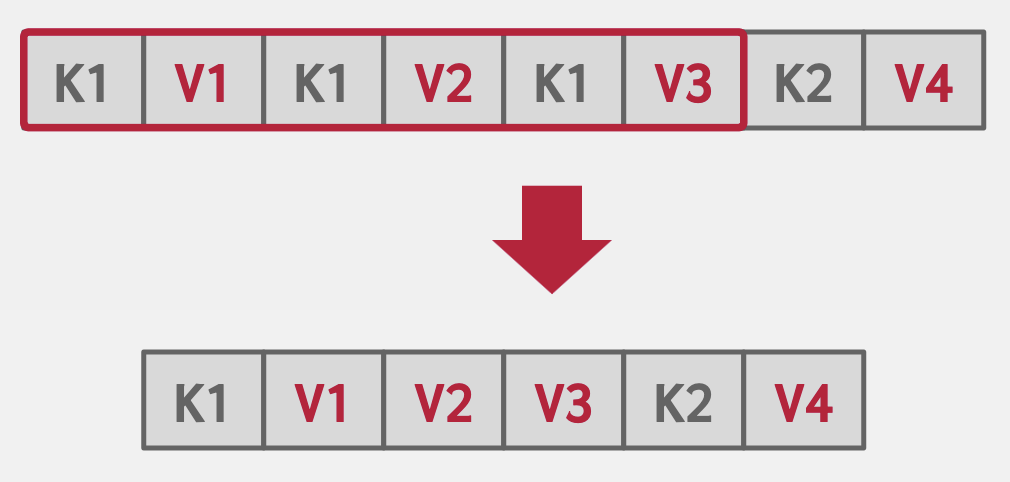
Deduplication
In the case of an index which allows non-unique keys, we may end up with leaf nodes containing the same key over and over with different values attached. One optimization of this could be only writing the key once and then following it with all of its associated values.
Suffix Truncation
For the most part the key entries in inner nodes are just used as signposts and not for their actual key value. We can take advantage of this by only storing the minimum prefix that is needed to correctly route probes into the correct node.
Write-Optimized B+Tree
Split / merge node operation are expensive. Therefore, some variants of B-Tree, such as Bϵ-Tree, logs changes in the internal node and lazily propagates the updates down to the leaf node later.
Some have bloom filters in front